AI-Ready数据集是什么?在科研领域有哪些应用?
发布时间:2025/03/19
在大数据、人工智能飞速发展的时代背景下,以大语言模型为代表的AI工具的应用受到了各方的高度重视,在各个关键科学研究领域和各类生产活动过程中愈发扮演着重要的角色。作为科学数据开放共享的国际通用原则,FAIR原则(Findable,Accessible,Interoperable and Reusable)在AI时代被赋予了新的内涵——Findable and AI Ready[1]。
一、基本概念
数据工作者有80%的时间需要投入数据的收集、清洗和转换过程。针对这一挑战,数据质量标准和AI-Readiness指标等概念逐步被提出,美国国家科学基金会(NSF)近日发布了《National AI Research Resource (NAIRR) Pilot seeks datasets to facilitate AI education and researcher skill development》(以下简称nsf2025),征集各领域高质量的AI-Ready数据集[2]。AI-Ready数据集是指经过系统化处理、标注和结构化的数据集合,专为人工智能模型的训练和评估设计。这类数据集通常具备高质量、标准化格式和清晰的标注,能够显著降低数据预处理的门槛,帮助研究人员和开发者快速投入模型开发。
二、核心特点
● 高质量标注:数据经过人工或自动化标注,标签准确且一致(如目标检测中的边界框、文本分类中的情感标签等)。
● 结构化格式:数据以通用格式存储(如CSV、JSON、TFRecord),适配主流框架(TensorFlow、PyTorch)。
● 数据分割:通常预分割为训练集、验证集和测试集,确保模型评估的公平性。
● 丰富元数据:附带数据来源、采集条件、标注规则等说明文档。
● 合规性与许可:明确的使用协议(如CC-BY、MIT许可证),避免法律风险。
三、常见应用领域
AI-Ready可广泛应用于计算机视觉、自然语言处理、语音处理、多模态任务等领域:
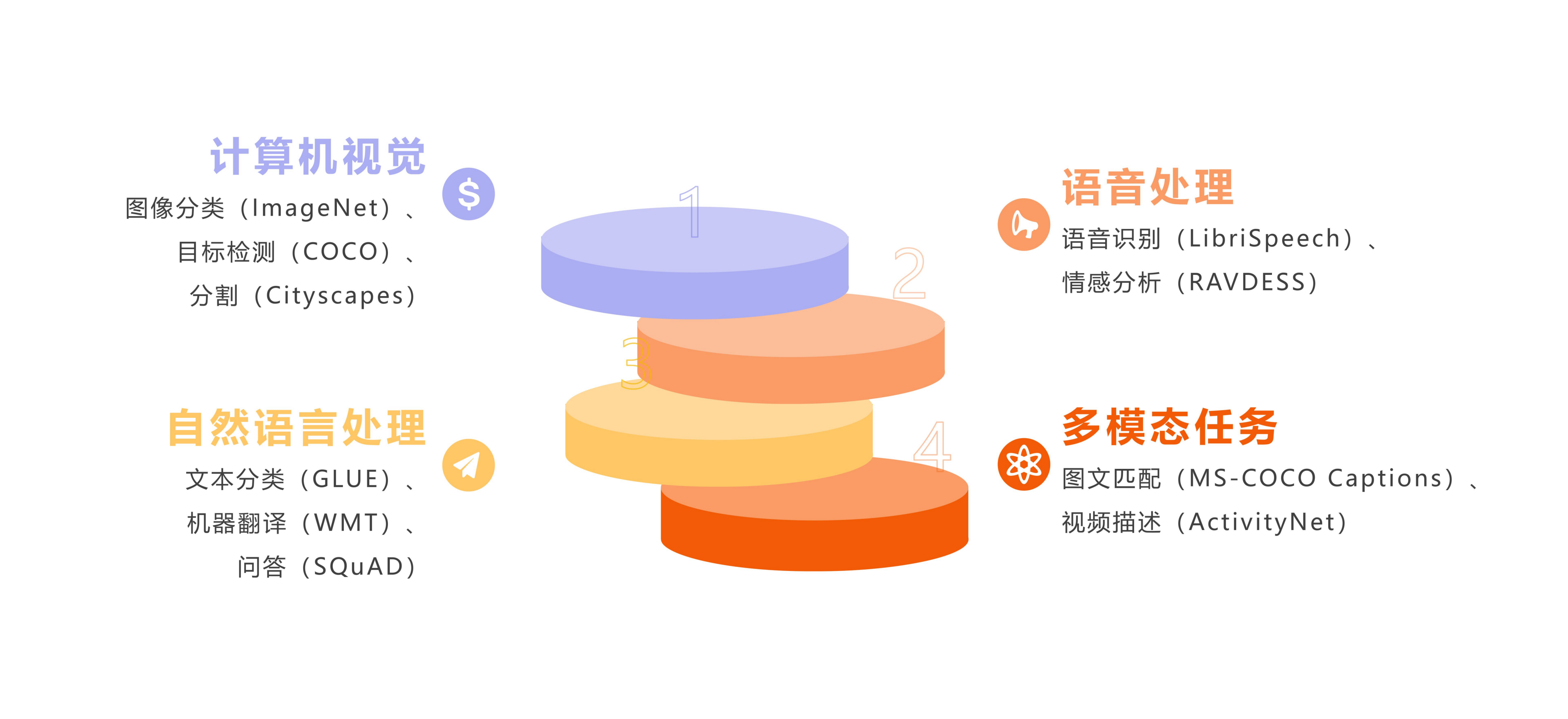
四、知名AI-Ready数据集示例
AI-Ready数据集在国外计算机视觉、NLP、语音识别等领域已投入使用:

五、构建AI-Ready数据集的步骤
1. 数据收集:从公开资源(Kaggle、政府开放数据)获取原始数据。
2. 清洗与去噪:剔除重复、错误或低质量样本(如模糊图像、无关文本)。
3. 标注与验证:人工标注(Amazon Mechanical Turk)或半自动工具(Label Studio),交叉验证确保质量。
4. 标准化处理:统一分辨率、文本编码、归一化数值特征。
5. 划分与封装:按比例划分数据集,封装为标准格式并提供加载脚本。
六、未来发展趋势
AI-Ready程度(AI-Readiness)指标仍然在发展和完善,值得思考的是,AI-Ready在我国科学数据领域具有广阔的发展前景:
1.当前我国存在数据供给质量不高、流通机制不畅、应用潜力释放不够等问题。在此背景下,大模型有望充当突破制度瓶颈的抓手,激活科学数据开放共享机制,充分释放科学数据要素价值化红利[3]。
2.加强科学数据集成,改进传统的数据组织方式,尤其是重点关注从分散到关联的深度数据集成方法,生产高质量的集成数据产品[4]。
3.发展“实用”的数据智能方法与大模型,推进大模型向领域应用纵深发展,真正实现行业的精准服务[5]。
参考文献:
[1]Scheffler M,Aeschlimann M,Albrecht M,et al. FAIR Data Enabling New Horizons for Materials Research[J]. Nature,2022,604(7907):635-642.
[2]国家天文科学数据中心.美国国家科学基金会如何定义AI-Ready数据集.https://nadc.china-vo.org/article/20241219164120,2024-12-19.
[3]王正超.科学数据开放共享中的大模型应用:前景、风险与治理[J/OL].现代情报,1-15[2025-03-14].http://kns.cnki.net/kcms/detail/22.1182.G3.20241203.1208.004.html.
[4]李新,苏建宾.走向数据善治:以地球科学数据治理为例[J].科学通报,2024,69(09):1149-1155.
[5]何国金,刘慧婵,杨瑞清,等.遥感数据智能:进展与思考[J].地球信息科学学报,2025,27(02):273-284.
